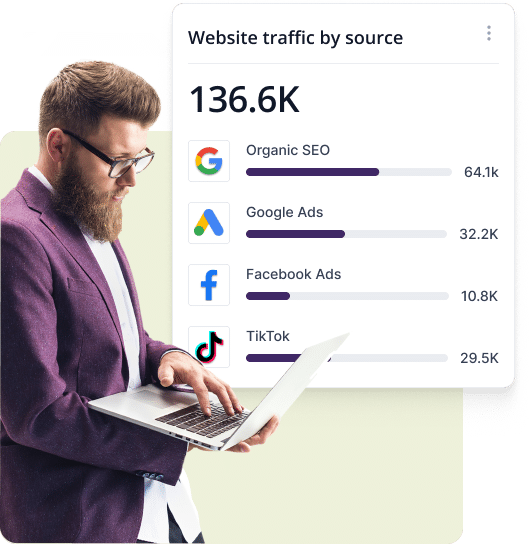
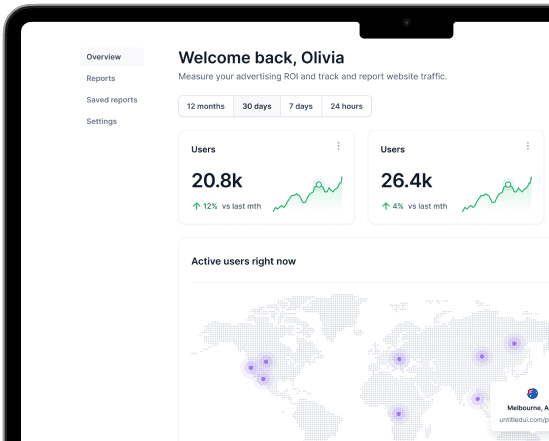
Some marketing agencies prefer to work with freelance marketers to fulfill their clients’ needs. But while this route may seem inexpensive, there are definite downsides.
For one thing, you’ll quickly hit a cap as to how much work you can outsource to a single freelancer. They’ll be limited by their own bandwidth issues, which means you won’t have the capacity to take on new clients or deliver services quickly. What’s more, you’ll have to thoroughly evaluate your freelance candidates to ensure they’re actually able to deliver on their promises. And even if they seem great in the beginning, you won’t have much recourse if they take on too many clients or ghost you. That can leave you in the lurch and make clients more vulnerable to churn. Plus, quality control can be an issue with many independent contractors. You may have to spend more of your time editing their work or requesting status updates, which means taking time away from sales, customer service, and other core areas of your business.
With independent contractors, you’ll get what you pay for (and sometimes, you may not even get that!). Working with a white label agency means you’ll get better transparency, quality control, and guaranteed on-time delivery. Our team is 100% USA-based, so you won’t have to worry about communication drop-offs or low-quality deliverables. We’re completely accountable to our work and our partners, so you can feel confident that we make good on our promises.